
Computer Vision in 2026: Foundation Models, "Locate Anything," and What Actually Changed
- I Chishti

- Jun 7
- 10 min read

Introduction: The Ground Has Shifted
A little under a year ago, we published a detailed field guide on building a computer vision system for object identification, counting, and ERP integration. The core message of that post still holds: getting from "the AI sees an object" to "the record in your system is correct" is a journey full of non-obvious problems — duplication, occlusion, lighting drift, object similarity, and knowing when to trust the machine.
What has changed in the months since is not the difficulty of those last-mile problems. It is the starting line. The arrival of vision foundation models — large, general-purpose models that can find and describe almost anything from a plain-language prompt — has rewritten the economics of the early stages of a computer vision project. Work that used to require collecting thousands of labelled images and training a bespoke detector for each new deployment can now, in many cases, begin with a model that already understands the world.
This post is a map of what actually changed. We will look at the shift from custom-trained detectors to prompt-driven foundation models, walk through the 2026 model landscape, take an honest look into NVIDIA's new "Locate Anything" model — what it is and, just as importantly, what it is not — and finish with where the whole category is heading and how to make practical decisions about it today.
What Actually Changed: From Custom Detectors to Vision Foundation Models
For most of the last decade, a computer vision deployment followed a predictable arc. You defined the objects you cared about, collected and labelled a large dataset of example images, trained a detector such as a YOLO or Faster R-CNN variant, and then maintained that model as the environment evolved. The model was narrow by design: it knew your classes and nothing else. Adding a new object type meant collecting new data and retraining.
The shift now underway is from this closed-set, train-per-task approach to open-vocabulary, prompt-driven perception. A modern vision foundation model is trained on enormous, diverse datasets and can localise objects it was never explicitly trained on, described in natural language. Instead of retraining to add a class, you change the prompt. "Find every safety helmet" and "find every cracked pallet" become configuration, not engineering projects.
This is the single most important change in the field, and it cuts in two directions. On the upside, time-to-first-result collapses, new object types cost almost nothing to add, and the long tail of rare objects becomes reachable. On the downside, these models are larger, hungrier for compute, and harder to control precisely than a small custom detector tuned for one job. The art in 2026 is knowing which problem deserves a giant generalist and which still wants a small, fast, predictable specialist.
The 2026 Vision Model Landscape
The market has organised itself into a handful of clear categories. No single model wins everywhere; the strongest deployments combine a generalist for flexibility with a specialist for speed. The table below maps the categories that matter and where each fits.

Category | Representative Model(s) | What It Does | Best For |
Generalist VLM Grounding | NVIDIA LocateAnything-3B (Eagle family) | Localises and points at almost anything from a natural-language prompt; open-set detection, referring-expression grounding, pointing, GUI and document grounding | Flexible perception across many object types; rapid prototyping and auto-labelling (research/non-commercial licence) |
Open-Vocabulary Detection | Grounding DINO, OWLv2, YOLO-World | Detects objects by text prompt without per-class training; bounding boxes for arbitrary categories | Teams that need zero-shot detection with a lighter footprint than a full VLM |
Promptable Segmentation | Segment Anything (SAM) family | Produces pixel-accurate masks for any object from a point, box, or prompt; image and video | Precise boundaries, area/volume estimation, cutouts, and measurement tasks |
Real-Time Specialist Detection | YOLO (latest generations), RT-DETR | Fast, fixed-class detection at high frame rates on modest hardware | High-throughput production counting on a known, stable set of classes; edge devices |
Multimodal Understanding | NVIDIA Nemotron, Qwen-VL, and other large VLMs | Answers questions about an image or video, reads scenes, reasons over visual context | Inspection reasoning, scene description, and agentic workflows that combine sight with decisions |
Tracking & Video | ByteTrack, DeepSORT, SAM 2 (video) | Assigns and maintains object identities across frames; segments and follows objects through video | Live environments with movement; deduplication and continuous counting over time |
The practical takeaway: no single row wins. The most capable deployments pair a generalist (for flexibility and rare object types) with a specialist (for speed and predictable production behaviour), and add a tracker when objects move.
NVIDIA's "Locate Anything"
The model generating the most attention in this space right now is NVIDIA's LocateAnything-3B, released as part of the company's Eagle family of vision-language models. It is worth understanding clearly, because it is a good representative of where the whole category is going — and because the hype around "locate anything" naming can obscure what the model actually does.
At its core, LocateAnything is a vision-language model for visual grounding: you give it an image and a natural-language description, and it returns precise locations — bounding boxes or points — for what you asked about. It handles open-set and long-tail object detection, dense detection in cluttered scenes, referring-expression grounding ("the second box from the left on the top shelf"), point-based localisation, GUI element grounding, and document layout and text localisation. In other words, it is a generalist locator rather than a single-purpose detector.

The headline technical idea is Parallel Box Decoding (PBD). Most vision-language models generate coordinates the way they generate text: one token at a time, autoregressively. LocateAnything instead predicts the complete coordinates of a bounding box in a single parallel step. The result, according to NVIDIA, is up to 2.5x higher throughput than prior approaches while preserving the geometric consistency of the boxes. For anyone who has waited on a large model to emit detections one number at a time, that is a meaningful difference.
Architecturally, the 3B-parameter model combines a native-resolution vision encoder (MoonViT) with a Qwen2.5-3B-Instruct language model and an MLP projector, trained across a deliberately broad dataset spanning natural scenes, robotics, driving, GUI interaction, and document understanding. That breadth is the point: it is designed as a foundation for general-purpose perception, and NVIDIA has folded its grounding capability into larger production models in its Nemotron line for agentic and GUI use cases.
What Locate Anything Is — and What It Is Not
This is the section that matters most for anyone planning to build with it, because the gap between the name and the reality is where projects go wrong.
What it is. It is a fast, flexible, general-purpose grounding engine. It is genuinely strong at finding things described in natural language, across domains, in cluttered scenes, without per-class training. It is excellent for rapid prototyping, for auto-labelling datasets you will later use to train a smaller production model, for open-set detection where the list of objects is long or unpredictable, and for the kind of GUI and document grounding that powers agentic systems. If your problem is "I need to locate things I can describe in words," this class of model is a powerful starting point.
What it is not. First, it is not a commercial product you can drop into a paying system today. LocateAnything-3B is released under NVIDIA's non-commercial research licence — explicitly for research and development. Commercial deployment requires a different licensing path, and treating the open weights as production-ready for a customer-facing system would be a licensing mistake, not just an engineering one. Always confirm the licence terms for your specific use before building on any model.
Second, it is not a complete counting-and-integration system. As we laid out in our earlier field guide, locating an object is only the first stage. The model finds things; it does not deduplicate across overlapping camera angles, reconcile a moving environment, decide when a low-confidence detection needs a human, push idempotent records into your ERP, or maintain an audit trail. Those stages — the genuinely hard last mile — remain exactly as hard as before.
Third, it is not free of the usual model caveats. It runs best on serious GPU hardware (NVIDIA's own testing references H100-class accelerators), it can produce confident-but-wrong detections, and its output is sensitive to how you phrase the prompt. Like any model, it needs to be measured against independent ground truth rather than trusted on its own say-so.
The honest summary: Locate Anything makes the perception stage dramatically more capable and flexible. It does not make the system around the perception stage disappear.
How This Slots Into a Real Deployment
The most useful way to think about foundation models is not "do they replace my pipeline?" but "which stages of my pipeline do they compress?"
In our earlier object-counting field guide, we described a deployment as a sequence of stages: scoping, a context-first survey of the environment, the core detection and counting, deduplication, human-in-the-loop review, accuracy measurement, and ERP integration. Foundation grounding models like Locate Anything change the economics of the front of that sequence while leaving the back of it almost untouched.
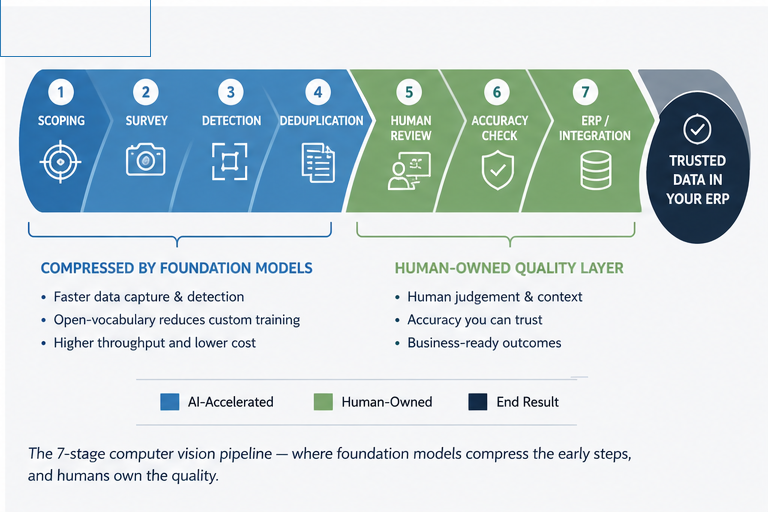
Where they help most. The detection stage is transformed. Instead of collecting and labelling thousands of images to train a detector before you can count anything, you can prompt a grounding model and get usable detections on day one. Adding a new object type — a new SKU, a new piece of equipment — becomes a prompt change rather than a retraining cycle. And the model can be used to auto-label data, accelerating the creation of a smaller, faster specialist model for production.
Where nothing changes. Deduplication across angles and time, confidence-based routing to human reviewers, independent accuracy measurement against ground truth, idempotent ERP writes, and a full audit trail are all still required, and still the parts that determine whether the system can be trusted. A more capable detector does not deduplicate itself, and it does not integrate itself into your system of record.
The strategic implication is encouraging: foundation models lower the barrier to starting a computer vision project and widen the range of problems that are now economically viable — while the engineering discipline that separates a demo from a dependable production system remains exactly where the real value is created.
Adoption Pitfalls in the Foundation-Model Era
The new generation of models brings a new generation of mistakes. These are the ones we see most often.
The licensing cliff. The single most common error is building a commercial proof-of-concept on research-only weights, then discovering at deployment time that the licence does not permit the use. Check the licence before you build, not after. Non-commercial means non-commercial.
The compute reality. Large grounding and multimodal models are impressive, but they are not free to run. If your deployment needs real-time performance at the edge, a giant generalist on H100-class hardware is the wrong tool — you will want a distilled or specialist model. Match the model to the latency, cost, and hardware constraints of where it actually has to run.
Trusting zero-shot accuracy. The ease of getting a result from a prompt makes it tempting to skip rigorous evaluation. Do not. A model that looks impressive in a demo can quietly miss 15% of objects in your specific environment. Measure precision and recall against an independent physical count, exactly as you would with a custom model.
Prompt sensitivity. Open-vocabulary output depends heavily on phrasing. "Box," "carton," and "package" can return different results on the same image. Treat prompts as part of your configuration: version them, test them, and document the ones that work.
Hallucinated detections. Generative models can confidently locate things that are not there. Confidence-based human review and ground-truth sampling are not optional safeguards in this era — they are the mechanism that catches a class of error that did not exist in the same way with traditional detectors.
Skipping the specialist. The most cost-effective production pattern is often to use a foundation model to bootstrap and auto-label, then train a small, fast specialist for the actual production workload. Teams that try to run the giant model in production for everything frequently pay for capability they do not need on every frame.
Where the Whole Category Is Going
Step back from any single model and a clear direction emerges.
Convergence into generalist perception. Detection, segmentation, grounding, and pointing used to be separate tools with separate models. They are merging into single vision-language models that do all of it from a prompt. Locate Anything's combination of boxes, points, GUI grounding, and text localisation in one model is an early, concrete example of that convergence.
From seeing to acting. The most consequential shift is the link between perception and action. Vision is increasingly the eyes of an agent — a robot, an autonomous system, or a software agent operating a GUI. Grounding models are being built specifically to feed downstream decisions, which is why GUI element grounding and pointing now sit alongside object detection in the same model. Vision is becoming a component of agentic systems rather than a standalone capability.
Edge-deployable small VLMs. The frontier models run in the data centre, but the pressure is downward. Distillation and smaller architectures are bringing open-vocabulary capability toward devices that can run on a factory floor or in a vehicle. Expect the gap between "the impressive cloud model" and "what you can run at the edge" to keep narrowing.
Video as a first-class input. Static-image understanding is maturing; the active frontier is video — tracking, temporal consistency, and understanding events over time. For real-world counting and monitoring, where things move, this is the capability that matters most.
Vision as prompted configuration. The throughline of all of this is that vision is shifting from something you train to something you prompt. That lowers barriers, widens the set of solvable problems, and changes the skill profile of a computer vision team — from "can you train a detector?" toward "can you design, evaluate, and integrate a perception system responsibly?"
How Cluedo Tech Approaches This
We have built and deployed production computer vision systems — including the object identification, counting, deduplication, and ERP integration system described in our earlier field guide. The arrival of foundation models has not changed our core conviction: the model is the easy part, and the system around it is where success is won or lost.
Our approach to the new generation of vision models rests on a few principles. We choose the model to fit the constraint, not the headline — matching commercial-licence requirements, latency targets, and edge-versus-cloud realities to the problem rather than reaching for the biggest model by default. We use foundation models where they shine — rapid prototyping, open-set detection, and auto-labelling to bootstrap faster, cheaper specialist models for production. And we keep the disciplined last mile intact: deduplication, human-in-the-loop review, independent accuracy measurement, idempotent integration, and full auditability, because that is what makes a system trustworthy.
Foundation models like Locate Anything are a genuine step change in what computer vision can do and how quickly it can be stood up. Used well, they shorten the path from idea to working system dramatically. Used carelessly — ignoring licensing, skipping evaluation, or assuming the model replaces the pipeline — they produce impressive demos that never become dependable systems.
If you are weighing how to bring foundation models into a real computer vision deployment, or how to modernise an existing one, we would welcome the conversation. Request a meeting.
Sources & Further Reading
NVIDIA LocateAnything-3B model card (Hugging Face): https://huggingface.co/nvidia/LocateAnything-3B
NVIDIA Eagle vision-language models (GitHub, NVlabs/Eagle): https://github.com/NVlabs/Eagle
Cluedo Tech — Computer Vision for Object Identification, Counting & ERP Integration: https://www.cluedotech.com/post/computer-vision-for-object-identification-counting-erp-integration


